Building a Climate dashboard
We're going to build an interactive dashboard of global temperature data, after processing 1TB of data in a few minutes!
Install fused
pip install "fused[all]"
Read more about installing Fused here.
Authenticate in Fused
In a notebook:
from fused.api import NotebookCredentials
credentials = NotebookCredentials()
print(credentials.url)
Follow the link to authenticate.
Read more about authenticating in Fused.
Processing 1 month
ERA5 global weather data was ingested using Fused ingestion pipeline.
import fused
- DuckDB
- Pandas
@fused.udf
def udf(
month: str = "2024-01",
):
import duckdb
result = duckdb.sql(f"""
SELECT
datestr::VARCHAR as datestr,
ROUND(AVG(daily_mean), 2) as daily_mean_temp
FROM 's3://fused-asset/data/era5/t2m/datestr={month}-*/*.parquet'
GROUP BY datestr
ORDER BY datestr
""").df()
output_fp = fused.file_path(f"monthly_climate/{month}.pq")
result.to_parquet(output_fp)
return result
NOTE: pandas approach is a bit slower than DuckDB.
@fused.udf
def udf(month: str = "2024-01",):
import pandas as pd
files = fused.api.list(f"s3://fused-asset/data/era5/t2m/datestr={month}-")
dfs = [pd.read_parquet(file, columns=['daily_mean']).assign(datestr=file.split('datestr=')[1].split('/')[0]) for file in files]
result = pd.concat(dfs).groupby('datestr')['daily_mean'].mean().round(2).reset_index()
output_fp = fused.file_path(f"monthly_climate/{month}.pq")
result.to_parquet(output_fp)
return result
fused.run(udf)
>>> datestr daily_mean_temp
3 2024-01-04 277.36
4 2024-01-05 277.26
5 2024-01-06 277.17
20 years of data (1TB in < 1min!)
Explore the available data for yourself in File Explorer
We'll process 20 years of data:
data_until = 2005
available_days = fused.api.list('s3://fused-asset/data/era5/t2m/')
recent_months = list(set([
path.split('datestr=')[1][:7] for path in available_days
if int(path.split('datestr=')[1][:4]) >= data_until
]))
This corresponds to ~1TB of data!
Size of data quick calculation
Each file being about 140MB a quick back of the envelope calculation gives us:
recent_days = [day for day in available_days if day.split('datestr=')[1][:7] in recent_months]
len(recent_days) * 140 / 1000 # size in GB of files we'll process
1005.62
Fused allows us to run a UDF in parallel. So we'll process 1 month of data across hundreds of jobs:
results = fused.submit(
udf,
recent_months,
max_workers=250,
collect=False
)
See a progress bar of jobs running:
results.wait()
See how long all the jobs took:
results.total_time()
>>> datetime.timedelta(seconds=40, ...)
We just processed 20 years of worldwide global data, over 1TB in 40s!!
All we need to do now is aggregate the data by month:
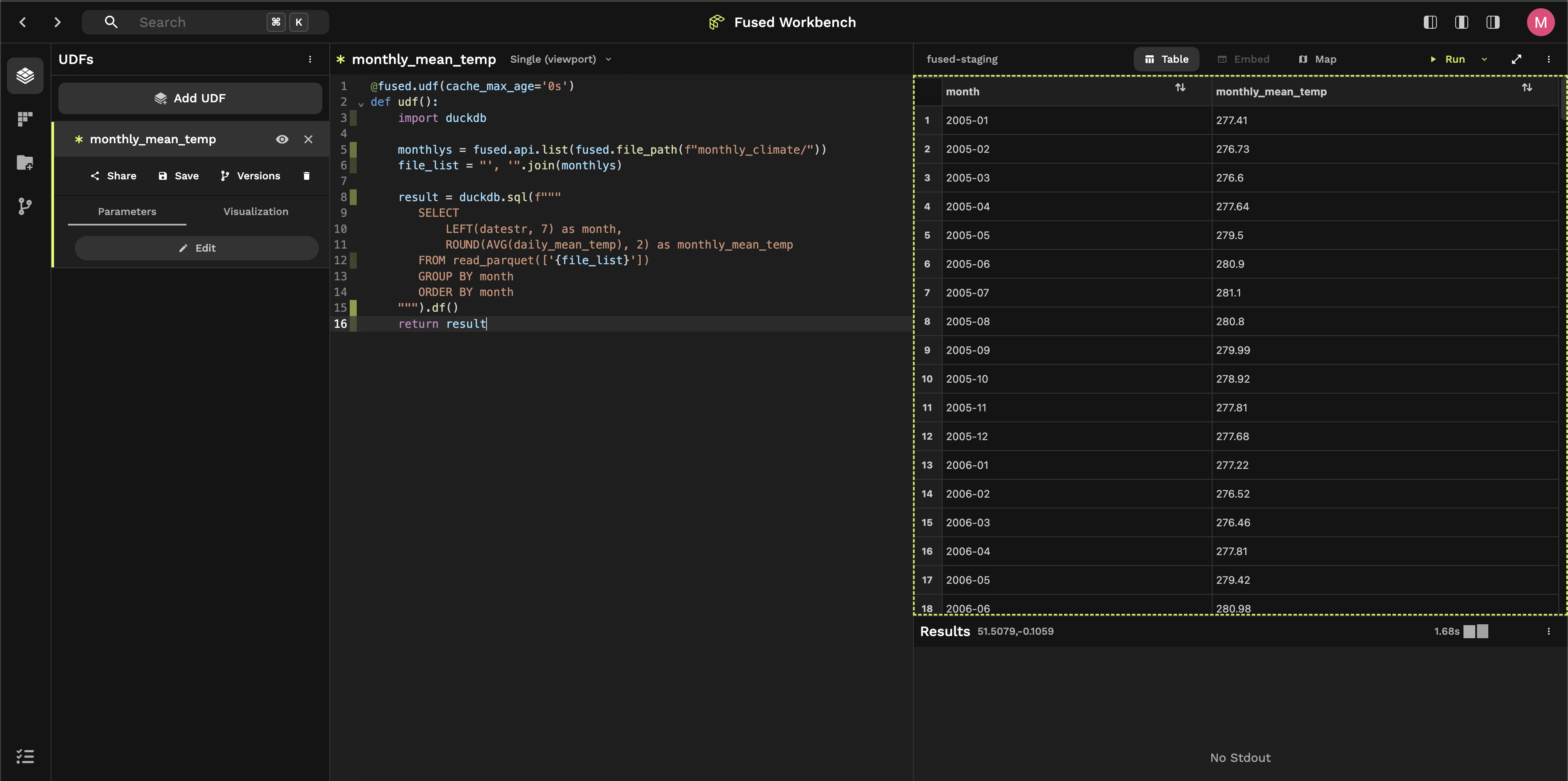
@fused.udf(cache_max_age='0s')
def udf():
import duckdb
monthlys = fused.api.list(fused.file_path(f"monthly_climate/"))
file_list = "', '".join(monthlys)
result = duckdb.sql(f"""
SELECT
LEFT(datestr, 7) as month,
ROUND(AVG(daily_mean_temp), 2) as monthly_mean_temp
FROM read_parquet(['{file_list}'])
GROUP BY month
ORDER BY month
""").df()
return result
Instead of running this locally, we'll open it in Workbench, Fused's web-based IDE:
# Save to Fused
udf.to_fused("monthly_mean_temp")
# Load again to get the Workbench URL
loaded_udf = fused.load("monthly_mean_temp")
Return loaded_udf in a notebook and you'll get a URL that takes you to Workbench:
loaded_udf
Click on the link to open the UDF in Workbench. Click "+ Add to UDF Builder"
Interactive graph (with AI)
You can use the AI Assistant to help you vibe code an interactive timeseries of your data
Simply ask the AI:
Make an interactive graph of the monthly temperature data
You can then share your graph:
- Save your UDF (
Cmd + S/ Click Save) - Click "Share"
- Create Shared token by clicking "Share"
- Click on link
Any time you make an update, your graph will automatically update!